In our previous two–part series we looked at the melt function from the reshape2 package. The creator of the package, Hadley Wickham, pointed me towards tidyr and the gather function as a better alternative instead.
So let’s take a look at gather:
Gather works in much the same way as melt – it gathers data from multiple columns into one column.
The basic syntax is as follows:
gather([your_data],[first_column],[second_column],[columns:tocombine]
It can be written another way using the %>% operator but we’ll stick with this for now. Full details are on the cheat sheet.
The first and second columns can be named how you like. Put the first column to combine to the left of the colon and the last to the right. In this example we will combine seven columns together.
We will use gather on data from the Department for Transport on the number of bus journeys made over several years around England. I cleaned up the data and made it available here for you to follow along.
Here it is:
> data <- read.csv("buses.csv")
> str(data)
'data.frame': 97 obs. of 9 variables:
$ LA.Code : Factor w/ 97 levels "E06000001","E06000002",..: 1 2 3 4 5 6 7 8 9 10 ...
$ Local.Authority: Factor w/ 97 levels "Bath and North East Somerset",..: 31 45 64 76 16 29 85 3 4 36 ...
$ X2009.10 : num 5.4 10.2 5.7 10.2 8.2 6 10.8 4.9 12.8 26.1 ...
$ X2010.11 : num 5.3 10.4 5.5 10 7.9 6.1 11.1 4.9 11.8 24.3 ...
$ X2011.12 : num 4.8 9.8 4.7 9.5 7 5.8 10.5 4.8 11.7 24.2 ...
$ X2012.13 : num 4.6 9.1 4.3 9.2 6.6 5.4 9.8 4.1 11.2 23.4 ...
$ X2013.14 : num 4.6 9 4.3 8.8 6.6 5.3 8.9 4.2 11.1 24 ...
$ X2014.15 : num 4.7 8.4 4.1 8.7 6.5 5.3 7.9 4 11.1 23 ...
$ X2015.16 : num 4.7 8.3 3.9 8.5 6.2 5.6 6.9 4 10.8 23 ...
It’s in much the same format as our drugs data, with the years spread across multiple columns.
gathered <- gather(data, year, journeys,X2009.10:X2015.16)
Here we are telling R: ‘Create two new columns called ‘year’ and ‘journeys’, using the data and column names from X2009.10 to X2015.16′.
> str(gathered) 'data.frame': 679 obs. of 4 variables: $ LA.Code : Factor w/ 97 levels "E06000001","E06000002",..: 1 2 3 4 5 6 7 8 9 10 ... $ Local.Authority: Factor w/ 97 levels "Bath and North East Somerset",..: 31 45 64 76 16 29 85 3 4 36 ... $ year : chr "X2009.10" "X2009.10" "X2009.10" "X2009.10" ... $ journeys : num 5.4 10.2 5.7 10.2 8.2 6 10.8 4.9 12.8 26.1 ...
This is the result. You can see that ‘year’ is now a column containing the column names from X2009.10 to X2015.16 and ‘journeys’ is a column containing all the corresponding values.
This data is now in a format to plot using geom_line.
The problem is we have a lot of local authorities in the data, which will likely result in overplotting if we try and plot of them.
Instead, let’s take the regions of England and plot them instead. There are nine regions in England which can be sub-divided into local authorities.

_-_de_-_colored.svg){kind=link}
Plotting these nine regions should give us a good indication of how often people take the bus around the country.
How do we find the regions in among those local authorities?
We find them by choosing the LA.Code column. The regions’ codes begin with ‘E12’.
#filter for regions
regions <- grep("E12",gathered$LA.Code)
regions <- gathered[regions, ]
That regular expression is looking in gathered$LA.Code for all the codes beginning E12, which gives us our nine regions.
Time to plot the graph
p <- ggplot(regions, aes(x = year, y = journeys,
group = Local.Authority, color = Local.Authority))
+ geom_line(size = 1.5)
+ ggtitle("Bus journeys by region")
+ labs(x = "Year", y = "Journeys (1000s)")
#create labels
labelss <- c("09/10","10/11","11/12","12/13","13/14","14/15","15/16")
#add labels to x axis
p <- p + scale_x_discrete(labels = labelss)
+ theme(plot.title = element_text(size = 58),
axis.text.y = element_text(size = 24),
axis.text.x = element_text(size = 20),
axis.title = element_text(size = 26),
legend.title = element_text(size = 28),
legend.text = element_text(size = 20),
legend.position = "right",
#space out the legend keys
legend.key.size = unit(1.5, 'lines'))
#relabel legend
p <- p + scale_color_discrete(name ="Region")
p
There are two new features to look out for in our line plot code:
-
Renaming the legend title
-
Spacing out the legend keys
Relabel the legend title with scale_color_discrete and space the keys out with legend.key.size as above.
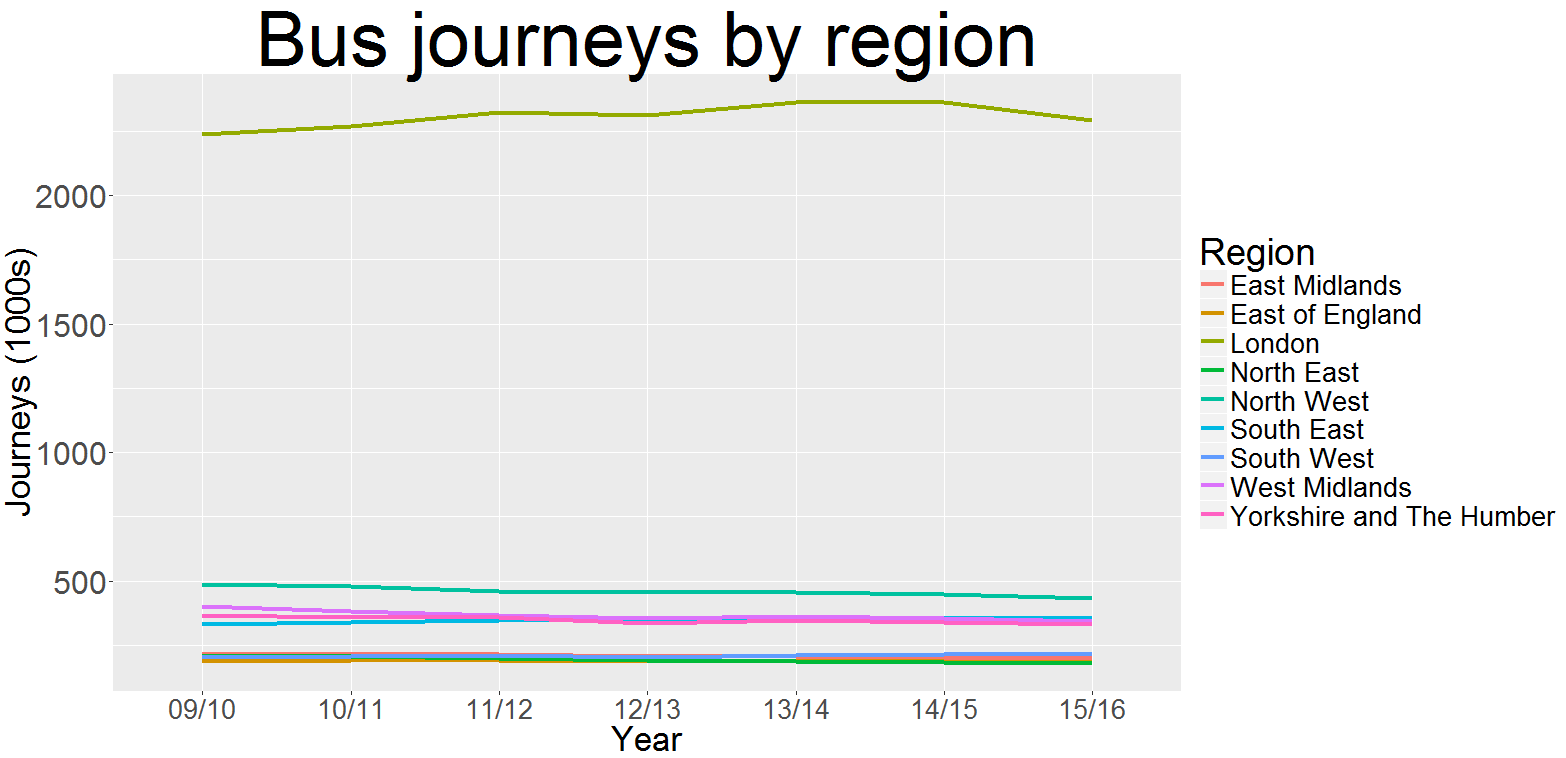
Here’s the result:

Analysis:
Londoners take the bus far more often than the rest of England.
In fact, one in two bus journeys across the entire country are made in the capital. In other words London takes the bus more often than the rest of England put together.
You would expect bus use in London to be high given that it has a lot of people who are likely to want to take short journeys.
But the same is true of other urban areas in England too.
Greater Manchester, for example, has less than a tenth of the bus use of London despite having slightly less than a third of its population.
So why is bus use so much higher in London?
It’s a good question but it’s not clear from the data.
There is clearly a huge gulf between London and the rest of the country but it’s not immediately obvious why that is the case.
The DfT’s report notes that Transport for London runs the London bus network, which is a different set-up from the rest of the country, but doesn’t say whether that has any impact on the willingness of people to use them.
The future
The Government wants bus services to be used more often. In its Bus Services Bill summary, it says:
Bus use has grown dramatically in London, rising by 31% since 2004/05 . There are many characteristics which set London apart from other areas across the country, such as population density and growth, and policy choices such as the congestion charge. London, however, has demonstrated that where bus networks are extensive, services frequent, and passengers have easy access to information about fares and services, bus patronage can increase.
The Bill is currently going through Parliament. When it’s passed into law, the new Greater Manchester mayor (and other devolved areas) will be able to decide what to do with buses themselves, in effect emulating the TfL model.
To me, this sounds like a good idea.
London’s buses are the most used in the country, and it has a different model from the rest of the country.
If we apply the same model to similar cities, we should (in theory) begin to get similar results.