See
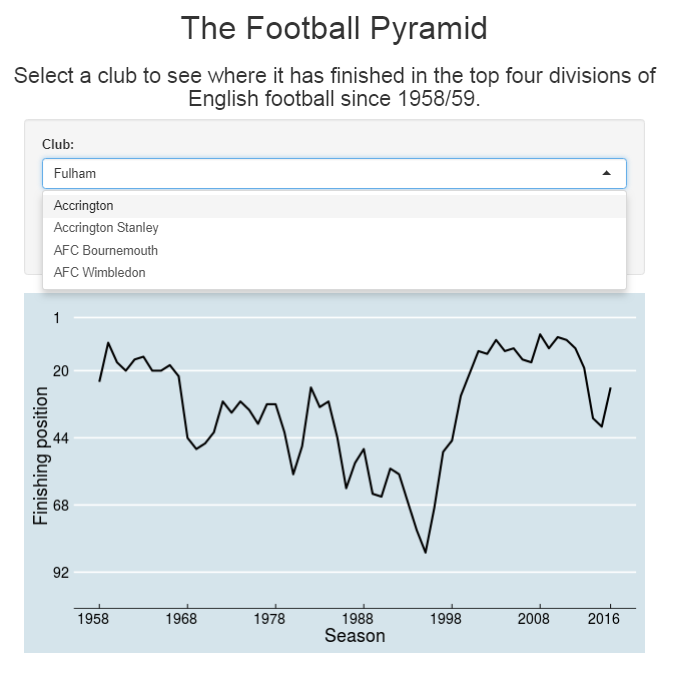
Recap In the last post we got to the stage where we had the data for each club’s league positions since 1958/59 in a Google sheet. The next step is to visualise this data in a Shiny app. Shiny lets you create visualisations that your users can interact with, and they have slightly different code … Read More “My First Shiny App Part II: The Shiny code itself” »