The Office for National Statistics published some of its most interesting data last week – internal migration.
This is the movement of people within the UK of people who are already here, not counting people immigrating or emigrating from abroad.
The ONS publishes its headline estimates and also the full underlying data, containing each possible permutation of age (by year) and location (by local authority).
Here’s one of my stories that came out of this data.
We want to see where people are moving from and to in England and Wales.
Let’s take a look at the data, which comes in two parts:
pt1 <- read.csv("Detailed_Estimates_2016_Dataset_1.csv")pt2 <- read.csv("Detailed_Estimates_2016_Dataset_2.csv")
#join two together
data <- rbind(pt1, pt2)
It’s always useful to call str on the data to see what it looks like:
> str(data)'data.frame': 1282336 obs. of 5 variables: $ OutLA: Factor w/ 350 levels "E06000001","E06000002",..: 1 1 1 1 1 1 1 1 1 1 ... $ InLA : Factor w/ 350 levels "E06000001","E06000002",..: 2 2 2 2 2 2 2 2 2 2 ... $ Age : int 0 1 3 5 5 6 7 8 8 9 ... $ Sex : Factor w/ 2 levels "F","M": 1 1 1 2 1 1 2 2 1 1 ... $ Moves: num 0.669 2.512 1.254 1.275 1.221 ...
The moves are the sums of each estimate. So a move of 2.512 means the ONS estimates that 2.512 people of that age group moved from one local authority to another in the year to June 2016.
The next step is to begin to group all this raw data by age and local authority.
There are probably lots of ways to do this, but a simple way is to use the summarise function of the dplyr package:
library(dplyr) first <- data %>% group_by(OutLA, InLA) %>% summarise (sum = sum(Moves)) LA_totals_in <- data %>% group_by(InLA) %>% summarise (sum = sum(Moves)) LA_totals_out <- data %>% group_by(OutLA) %>% summarise (sum = sum(Moves))
Here we are summing the Moves column (i.e. eliminating the individual ages of the movers) and grouping them by local authority.
First is grouping by both the original local authority (OutLA) and the new one (InLA), while LA_totals_in and LA_totals_out are providing just an overall outflow and inflow figure for each authority.
Our first data frame is very large because it has every combination of moves between the 348 local authorities in England and Wales (plus Scotland and Northern Ireland, which aren’t broken down by local authority), while the other two are only 350 rows long because they are the overall figures.
Next up we can use merge to bring LA_totals_in and LA_totals_out together. Subtracting one from the other gives us a net figure:
LA_totals <- merge(LA_totals_in, LA_totals_out, by.x = "InLA", by.y = "OutLA") #calculate net figure LA_totals$net <- LA_totals$sum.x - LA_totals$sum.y
At this point we can check our code is right against the ONS’s summary data. Take a look for yourself before we move on (year ending June 2016, tab 4).
Now we can get into some mapping.
One of the key packages for mapping in R is rgdal. Let’s load that up, along with these other two:
library(rgdal) library(sp) library(rgeos)
I found this hexagonal base map of local authorities in Britain. I like hexagon maps for two reasons:
- They are neat
- They remove the large disparities in physical size between local authorities.
The largest local authorities by land area tend to be sparsely populated areas such as Cumbria or Cornwall, while London boroughs often don’t show up well in KML maps. Hexagonal maps even out these discrepancies.
Download the map and put all the files in your directory.
We are going to colour the hexagons based on whether there was a net gain or loss in the area due to internal migration.
We will do this using hex codes (appropriately enough). Every colour you see on the internet has a hex code – a unique ID that browsers use to display them.
We will set a new column of color and set it to NA for now:
LA_totals$color <- NA
Again, there are at least two ways of doing this. One is by using a for loop and the other is by using an apply function.
I was taken to task a bit on /r/rstats for my last post using for loops. Coming from a basic JavaScript background they were quite a natural choice for me, but I agree that the apply family is a tidier way of going about iterating simple formulas.
An apply function (there are several, this one is mapply) takes a formula and applies it to several different values.
This can be a pre-existing formula or one you create yourself. We’re going to create a formula ourselves.
color <- function (a, b) {
if (a >= 0) {
b = "#0000FF"
} else {
b = "#ff8000"
}
}
Our function takes two arguments, a and b. A is the value – if it’s greater than or equal to 0, give colour #0000FF to b. If not, give it the other colour.
You’ve probably guessed that a will be our net figure and b the color:
LA_totals$color <- mapply(FUN = color, a = LA_totals$net, b = LA_totals$color)
Now we read the shapefile, merge our data with it and plot:
hex <- readOGR(".","GB_Hex_Cartogram_LAs")
m <- merge(hex, LA_totals, by.x = "LAD12CD", by.y = "InLA")
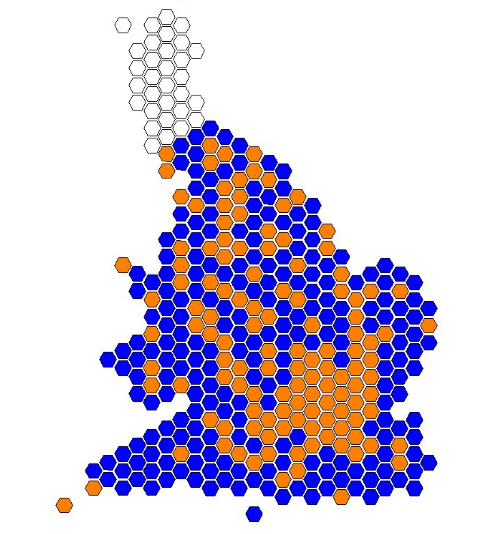
plot(m, col = m$color, lwd = 1, main = "Internal migration in England and Wales, year to June 2016", sub = "Blue = net gain\nOrange = net loss")
Here’s the result:
Playing around with hex cartograms in #rstats.
Internal migration 2015/16 – which areas gained people, which ones lost people: pic.twitter.com/EvSJhG79Jm
— Rob Grant (@robgrantuk) June 22, 2017
Analysis:
As the map subtitle shows, areas in blue had a net gain of people while orange had a net loss.
We can see that people are leaving London and heading for the shires.
This is also happening in the West Midlands and the northern cities such as Manchester, Hull and Newcastle. The South West is very popular.
Final thoughts:
One downside of hexagonal maps is that you can’t tell from a flat map exactly where a hexagon corresponds to. You need a basic level of geographical knowledge to understand the map – but we can always annotate it to bring out any particular highlights.
But this is also true of maps in general, and even so it shows at a glance what’s going on across England and Wales in a way you just don’t get with Google Fusion tables.
You may be wondering why we bothered with all this R code when we could have just downloaded the spreadsheet and gone from there.
Well, stay tuned for parts two and three, where we go even deeper into the data. We’ll need R for that.
UPDATE:
The code earlier was missing a line about reading the OGR hex file. Thanks to Paul Bradshaw for pointing it out!